7,507
Speeches analyzed
47 yrs
Coverage (1971–2018)
0.2896
Best silhouette score (LDA clusters)
Overview
The United Nations General Assembly is one of the richest archives in modern diplomacy — nearly five decades of member states articulating national priorities, reacting to crises, and negotiating a shared global agenda. This project applies two complementary topic-modeling approaches, Latent Dirichlet Allocation (LDA) and TopicGPT, to 7,507 UNGA speeches spanning 196 countries from 1971 to 2018, systematically uncovering how the themes of international diplomacy have shifted over time.
Data and Preprocessing
The raw corpus consists of speech transcripts organized by country code, session, and year. Each file was cleaned to remove paragraph numbers, salutations, non-speech annotations, and formatting artifacts. After normalization, the text was tokenized into sentences to preserve grammatical context — a step that proved especially important for TopicGPT's contextual embeddings.
A custom pipeline grouped speeches by date and extracted metadata (country, session, year) into a structured Pandas DataFrame, enabling downstream comparative analysis across time periods and geographies. The chart below tracks the steady growth in UN membership over the study period.
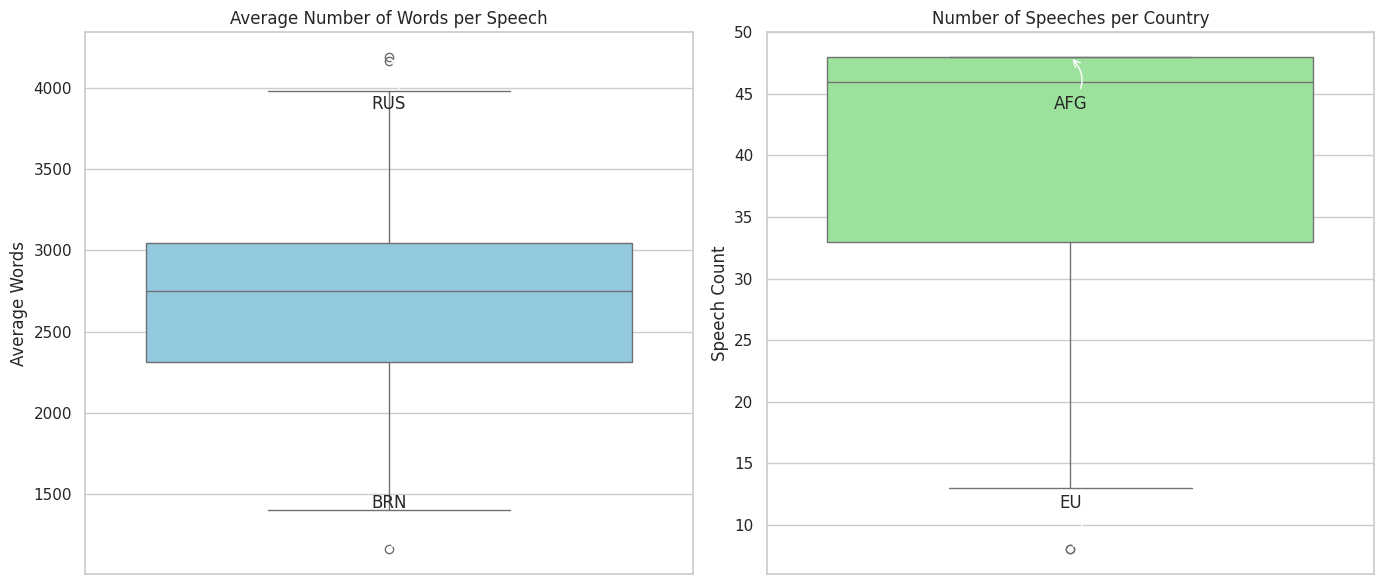
Distribution of speech length and participation frequency across member states
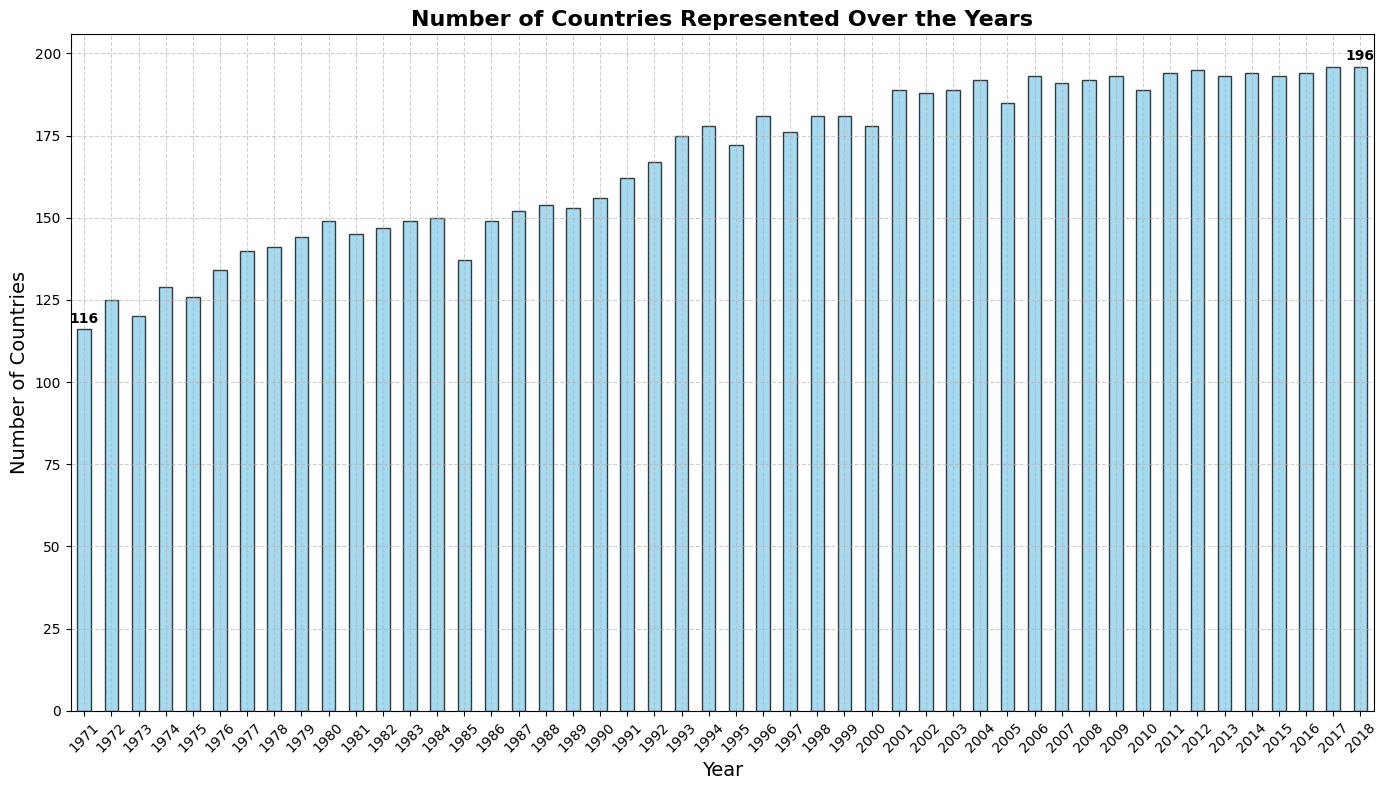
Steady increase in UN membership from 1971 to 2018
Modeling: LDA vs. TopicGPT
LDA is a probabilistic generative model that represents each document as a mixture of latent topics and each topic as a distribution over words. It completed in minutes, required no external API, and produced interpretable word-level topic distributions — ideal for rapid, broad thematic exploration.
TopicGPT leverages GPT-based contextual embeddings to cluster documents into topics, capturing semantic relationships that the bag-of-words assumption in LDA misses. The trade-off: significantly longer processing time, an OpenAI API key, and approximately $25 in compute cost. TopicGPT's output also arrived in non-uniform formats, requiring an additional cleaning pass to extract a consistent set of five keywords per entry before meaningful comparison was possible.
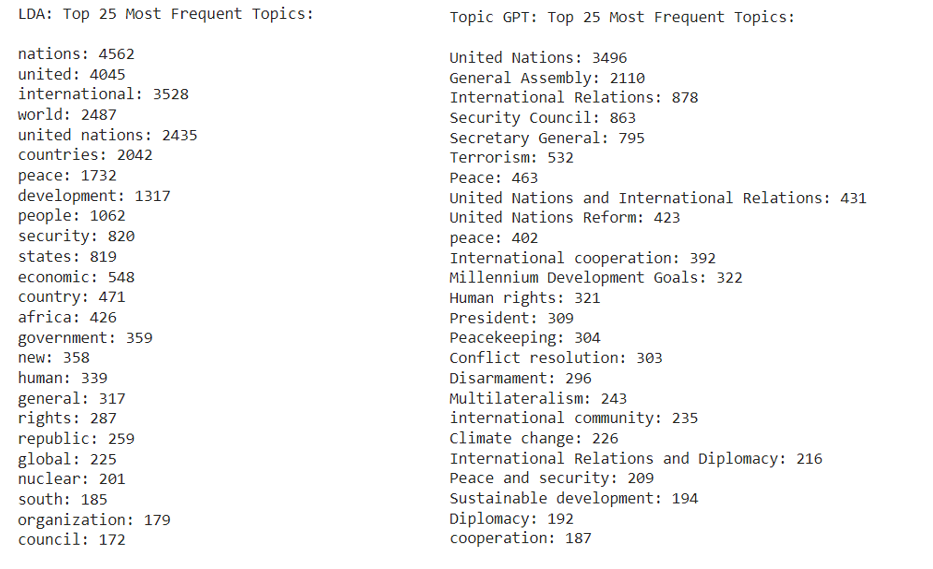
Top 25 most frequent topics — LDA (left) vs. TopicGPT (right)
LDA surfaces broad recurring terms: "united," "nations," "international," "peace," "security," and "development" dominate. TopicGPT resolves these into specific initiatives and issues — Millennium Development Goals (322 occurrences), Human rights (321), Disarmament (296), Climate change (226), and Sustainable development (194). The contrast reveals that LDA excels at identifying macro-level rhetorical patterns while TopicGPT tracks the concrete agenda items that actually moved through the Assembly.
Word Clouds and Cluster Analysis
To visualize thematic differences, word clouds were generated from the top 100 topics of each model. LDA's cloud is anchored by sovereignty-era language; TopicGPT's reflects the post-Cold War shift toward human-security and development frameworks.

LDA — top 100 topics

TopicGPT — top 100 topics
KMeans clustering (k‑means++ initialization) was applied to TF-IDF vectors of both model outputs. Two clusters emerged in each case. For LDA the optimal configuration required 20 initializations and achieved a silhouette score of 0.2896; TopicGPT's best configuration used 10 initializations and scored 0.2139. LDA's higher cohesion reflects its tighter word-level signal; TopicGPT's broader embeddings produce softer cluster boundaries.
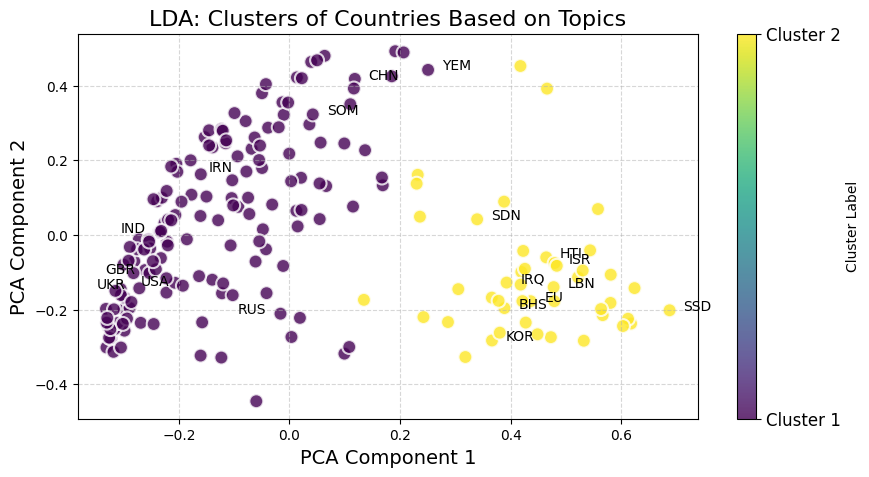
LDA clusters — PCA projection by country
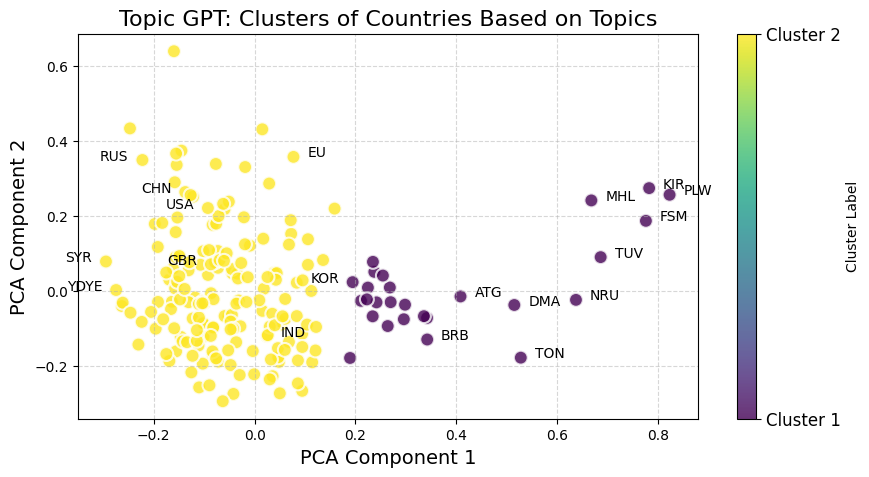
TopicGPT clusters — PCA projection by country
The LDA cluster plot groups major powers (USA, UK, Russia, China) together around global-governance themes, while a second cluster captures countries whose speeches center on regional or developmental concerns (Iraq, South Sudan, Haiti). TopicGPT produces a different alignment: Russia, China, and the USA cluster around international-relations discourse, while small island states (Tonga, Nauru) form a separate group centered on climate vulnerability and regional sovereignty. The two models are thus complementary — LDA maps the structural cleavages of global politics; TopicGPT maps the issue-level ones.
Key Findings
LDA and TopicGPT together tell a coherent story about five decades of UNGA discourse. Both models confirm the centrality of peace, security, and international cooperation as enduring themes. TopicGPT additionally reveals the mainstreaming of climate change, human rights, and sustainable development — topics that barely registered in the 1970s corpus but dominate the post-2000 sessions. The dual-clustering approach demonstrates that geopolitical blocs (global powers vs. developing states) are legible from the text alone, without any prior labeling.
For policymakers the implication is practical: automated topic modeling at this scale can surface diplomatic shifts years before they crystallize into treaty language, providing an early-signal layer for foreign-policy analysis. For researchers, the gap between LDA's broad themes and TopicGPT's specific entities points to a productive direction — combining probabilistic models with contextual embeddings yields richer thematic maps than either approach alone.